Twitterт╣┐тЉіт╣│тЈ░т«ъТЌХУ«АУ┤╣у│╗у╗ЪуџёТъХТъётбът╝║С╣ІжЂЊ
 ТгА
ТгА
Twitter Тў»т╣┐тЉітЋєтљИт╝ЋтЈЌС╝ЌуџёСИђСИфуЃГжЌет╣│тЈ░сђѓтйЊт╣┐тЉітЋєтЈЉУхиСИђСИфТќ░уџёт╣┐тЉіТ┤╗тіе№╝їт«ЃС╗гС╝џжЎљт«џСИђСИфт╣┐тЉіжбёу«ЌсђѓTwitter уџёт╣┐тЉіТюЇтіАтЎеС╝џТБђТЪЦт╣┐тЉіТ┤╗тіеуџёжбёу«Ќ№╝їС╗ЦСЙ┐уА«т«џТў»тљдУ┐ўУЃйу╗Ду╗ГТіЋТћЙт╣┐тЉісђѓтдѓТъюТ▓АТюЅУ┐ЎСИфТБђТЪЦТю║тѕХ№╝їТѕЉС╗гтЈ»УЃйС╝џтюет╣┐тЉіТ┤╗тіеУЙЙтѕ░жбёу«ЌжЎљжбЮтљју╗Ду╗ГТЈљСЙЏт╣┐тЉіТюЇтіАсђѓТѕЉС╗гТііУ┐ЎуДЇТЃЁтєхтЈФСйюУХЁТћ»сђѓУХЁТћ»С╝џт»╝УЄ┤ Twitter уџёТћХтЁЦТЇЪтц▒(ућ▒С║јТю║С╝џТѕљТюгуџётбътіаРђћРђћСЙІтдѓ№╝їТѕЉС╗гТюгтЈ»С╗ЦтюежѓБСИфСйЇуй«ТўЙуц║тЁХС╗ќт╣┐тЉі)сђѓТЅђС╗Ц№╝їТѕЉС╗гУдЂт╗║уФІСИђСИфтЈ»жЮауџёу│╗у╗ЪТЮЦжў▓ТГбтЈЉућЪУХЁТћ»сђѓ
- УЃїТЎ»у«ђУ┐░ -
тюеТи▒тЁЦуаћуЕХУХЁТћ»Тў»тдѓСйЋтЈЉућЪтЅЇ№╝їтЁѕТЮЦС║єУДБСИђСИІТѕЉС╗гуџёт╣┐тЉіу│╗у╗ЪТў»тдѓСйЋТЈљСЙЏт╣┐тЉіТюЇтіАуџёсђѓСИІжЮбТў»ТѕЉС╗гт╣┐тЉіТюЇтіАу«АжЂЊуџёжФўу║ДТъХТъётЏЙ№╝џ
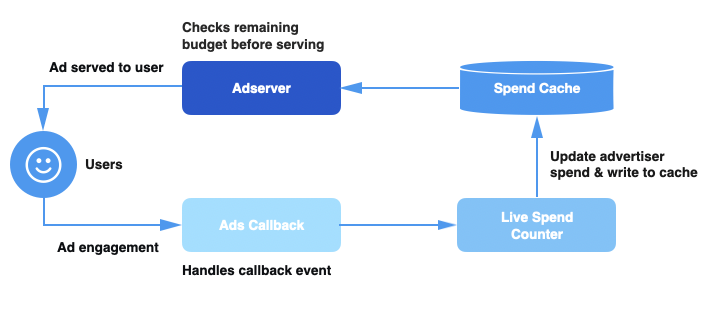
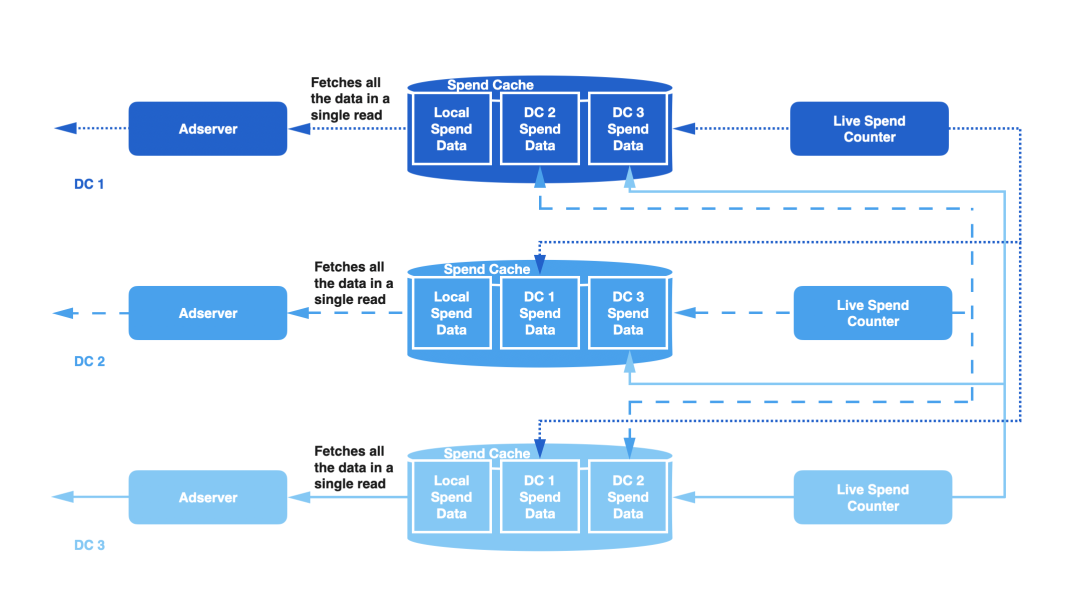
Тћ»тЄ║у╝ЊтГў№╝ѕSpend Cache№╝ЅРђћРђћСИђСИфтѕєтИЃт╝Ју╝ЊтГўТюЇтіА№╝їтЈ»С╗ЦУиЪУИфТ»ЈСИфт╣┐тЉіТ┤╗тіеуџётйЊтЅЇжбёу«ЌТћ»тЄ║сђѓ
т«ъТЌХт╣┐тЉіТћ»тЄ║У«АТЋ░тЎе(Live Spend Counter№╝їLSC)РђћРђћСИђСИфтЪ║С║ј Apache Heron уџёТюЇтіА№╝їУ┤ЪУ┤БУЂџтљѕт╣┐тЉіТ┤╗тіет╣ХТЏ┤Тќ░Тћ»тЄ║у╝ЊтГўсђѓ
т╣┐тЉітЏъУ░Ѓ№╝ѕAds Callback№╝ЅРђћРђћтцёуљєућеТѕиТхЈУДѕС║ІС╗Хуџёу«АжЂЊ№╝їСИ║С║ІС╗ХТи╗тіаСИіСИІТќЄС┐АТЂ»№╝їт╣Хт░єт«ЃС╗гтЈЉжђЂтѕ░ LSCсђѓ
т╣┐тЉіТюЇтіАтЎе№╝ѕAd Server№╝ЅРђћРђћтюетцёуљєУ»иТ▒ѓТЌХ№╝їтє│т«џТў»тљдт║ћУ»ЦС╗јт╣┐тЉіТћ»тЄ║у╝ЊтГўСИГУјитЈќтйЊтЅЇТ┤╗тіеуџёТћ»тЄ║сђѓжюђУдЂТ│еТёЈуџёТў»№╝їУ┐ЎжЄїТЅђУ»┤уџёт╣┐тЉіТюЇтіАтЎетїЁТІгС║єтљЉућеТѕиТЈљСЙЏт╣┐тЉіуџётцџуДЇТюЇтіАсђѓ
тйЊућеТѕитюе Twitter СИіТхЈУДѕт╣┐тЉіТЌХ№╝їТѕЉС╗гС╝џтљЉт╣┐тЉітЏъУ░Ѓу«АжЂЊтЈЉжђЂСИђСИфС║ІС╗ХсђѓСИђТЌдТ┤╗тіеТћ»тЄ║У«АТЋ░тЎеТћХтѕ░У┐ЎСИфС║ІС╗Х№╝їт«Ѓт░єУ«Ау«ЌТ┤╗тіеуџёТђ╗Тћ»тЄ║№╝їт╣ХтюеТћ»тЄ║у╝ЊтГўСИГТЏ┤Тќ░Т┤╗тіеуџёТћ»тЄ║сђѓт»╣С║јТ»ЈСИфС╝атЁЦуџёУ»иТ▒ѓ№╝їт╣┐тЉіТюЇтіАтЎеу«АжЂЊжЃйС╝џТЪЦУ»бТћ»тЄ║у╝ЊтГў№╝їС╗ЦСЙ┐УјитЙЌТ┤╗тіеуџётйЊтЅЇТћ»тЄ║№╝їт╣ХТа╣ТЇ«тЅЕСйЎуџёжбёу«ЌуА«т«џТў»тљду╗Ду╗ГТЈљСЙЏТюЇтіАсђѓ
- т╣┐тЉіжбёу«ЌУХЁТћ» -
тЏаСИ║ТѕЉС╗гтцёуљєуџёт╣┐тЉіТ┤╗тіеуџёУДёТеАТ»ћУЙЃтцД(ТЋ░ТЇ«СИГт┐ЃТ»ЈуДњТюЅТЋ░С╗ЦуЎЙСИЄУ«Ауџёт╣┐тЉіТхЈУДѕС║ІС╗Х)№╝їТЅђС╗Цт╗ХУ┐ЪТѕќуАгС╗ХТЋЁжџюжџЈТЌХжЃйтЈ»УЃйтюеТѕЉС╗гуџёу│╗у╗ЪСИГтЈЉућЪсђѓтдѓТъюТћ»тЄ║у╝ЊтГўТ▓АТюЅТЏ┤Тќ░ТюђТќ░уџёТ┤╗тіеТћ»тЄ║№╝їт╣┐тЉіТюЇтіАтЎет░▒С╝џУјитЈќтѕ░жЎѕТЌДуџёС┐АТЂ»№╝їт╣Ху╗Ду╗ГСИ║ти▓у╗ЈУЙЙтѕ░жбёу«ЌСИіжЎљуџёТ┤╗тіеТЈљСЙЏт╣┐тЉіТюЇтіАсђѓТѕЉС╗гт░єТ░ИУ┐юТЌаТ│ЋТћХтЈќУХЁтЄ║т╣┐тЉіжбёу«ЌуџёжѓБжЃетѕєУ┤╣уће№╝їт»╝УЄ┤ Twitter уџёТћХтЁЦТЇЪтц▒сђѓ
СЙІтдѓ№╝їтЂЄУ«ЙТюЅСИђСИфТ»ЈтцЕжбёу«ЌСИ║ 100 уЙјтЁЃуџёт╣┐тЉіТ┤╗тіе№╝їТ»ЈСИђТгАуѓ╣тЄ╗уџёС╗иТа╝СИ║ 0.01 уЙјтЁЃсђѓтюеТ▓АТюЅУХЁТћ»уџёТЃЁтєхСИІ№╝їУ┐Ўт░єСИ║Т┤╗тіетѕЏжђаТ»ЈтцЕ 10000 ТгАуѓ╣тЄ╗уџёТю║С╝џсђѓ

тЂЄУ«Йт╣┐тЉітЏъУ░Ѓу«АжЂЊТѕќ LSC тЄ║уј░ТЋЁжџю№╝їт»╝УЄ┤Тћ»тЄ║у╝ЊтГўТ▓АТюЅТЏ┤Тќ░№╝їСИбтц▒С║єС╗итђ╝ 10 уЙјтЁЃуџёС║ІС╗Х№╝їТћ»тЄ║у╝ЊтГўтЈфС╝џТіЦтЉіТћ»тЄ║СИ║ 90 уЙјтЁЃ№╝їУђїт«ъжЎЁСИіТ┤╗тіети▓у╗ЈТћ»тЄ║С║є 100 уЙјтЁЃ№╝їжѓБС╣ѕУ»ЦТ┤╗тіет░єУјитЙЌжбЮтцќуџё 1000 ТгАтЁЇУ┤╣уѓ╣тЄ╗Тю║С╝џсђѓ
- УиеТЋ░ТЇ«СИГт┐ЃСИђУЄ┤ТђД -
Twitter ТюЅтцџСИфТЋ░ТЇ«СИГт┐Ѓ№╝їТ»ЈСИфТЋ░ТЇ«СИГт┐ЃжЃйжЃеуй▓С║єТЋ┤СИфт╣┐тЉіТюЇтіАу«АжЂЊуџётЅ»Тюг№╝їтїЁТІгт╣┐тЉітЏъУ░Ѓу«АжЂЊсђЂт«ъТЌХТћ»тЄ║У«АТЋ░тЎетњїТћ»тЄ║у╝ЊтГўсђѓтйЊућеТѕиуѓ╣тЄ╗т╣┐тЉіТЌХ№╝їтЏъУ░ЃС║ІС╗ХУбФУи»ућ▒тѕ░тЁХСИГуџёСИђСИфТЋ░ТЇ«СИГт┐Ѓ№╝їУ┐ЎСИфТЋ░ТЇ«СИГт┐ЃжЄїуџётЏъУ░Ѓу«АжЂЊт░єУ┤ЪУ┤БтцёуљєУ┐ЎСИфС║ІС╗Хсђѓ
жѓБС╣ѕ№╝їжЌ«жбўт░▒ТЮЦС║є№╝џТ»ЈСИфТЋ░ТЇ«СИГт┐ЃУ«Ау«ЌуџёТђ╗Тћ»тЄ║тЈфУ«Ау«ЌУ»ЦТЋ░ТЇ«СИГт┐ЃТјЦТћХтѕ░уџёС║ІС╗Х№╝їСИЇтїЁТІгтЁХС╗ќТЋ░ТЇ«СИГт┐ЃуџёТЋ░ТЇ«сђѓућ▒С║јт╣┐тЉіт«бТѕиуџёжбёу«ЌТў»УиеТЋ░ТЇ«СИГт┐Ѓуџё№╝їУ┐ЎТёЈтЉ│уЮђТ»ЈСИфТЋ░ТЇ«СИГт┐ЃуџёТћ»тЄ║С┐АТЂ»Тў»СИЇт«їТЋ┤уџё№╝їтЈ»УЃйС╝џт░Љу«ЌС║єт╣┐тЉіт«бТѕиуџёт«ъжЎЁТћ»тЄ║сђѓ
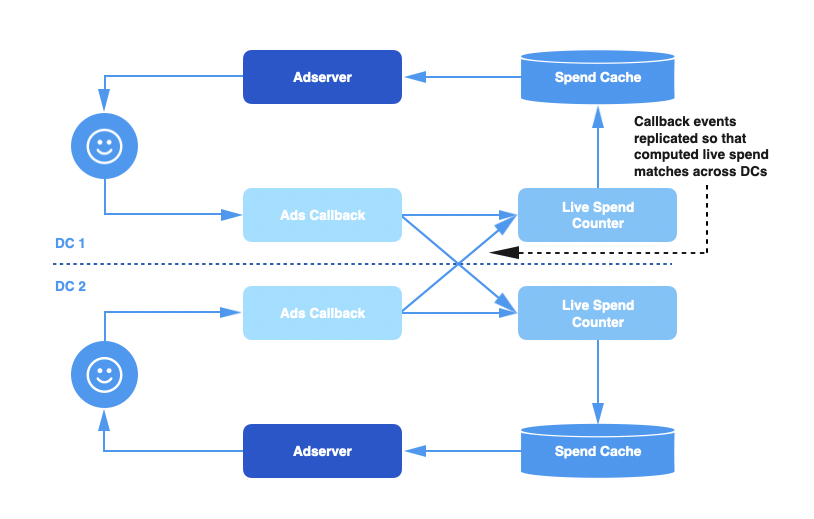
СИ║С║єУДБтє│У┐ЎСИфжЌ«жбў№╝їТѕЉС╗гу╗ЎтЏъУ░ЃС║ІС╗ХжўЪтѕЌТи╗тіаС║єУиеТЋ░ТЇ«СИГт┐ЃтцЇтѕХтіЪУЃй№╝їС╗ЦСЙ┐У«ЕТ»ЈСИфТЋ░ТЇ«СИГт┐ЃжЃйУЃйтцЪтцёуљєТЅђТюЅуџёС║ІС╗ХсђѓУ┐ЎуА«С┐ЮС║єТ»ЈСИфТЋ░ТЇ«СИГт┐ЃСИГуџёТћ»тЄ║С┐АТЂ»Тў»т«їТЋ┤тњїтЄєуА«уџёсђѓ
- тЇЋСИфТЋ░ТЇ«СИГт┐ЃуџёТЋЁжџю -
т░йу«АтцЇтѕХС║ІС╗ХСИ║ТѕЉС╗гтИдТЮЦС║єТЏ┤тЦйуџёСИђУЄ┤ТђДтњїТЏ┤тЄєуА«уџёТћ»тЄ║С┐АТЂ»№╝їСйєу│╗у╗Ъуџёт«╣жћЎУЃйтіЏС╗ЇуёХСИЇТў»тЙѕт╝║сђѓСЙІтдѓ№╝їТ»ЈжџћтЄатЉе№╝їУиеТЋ░ТЇ«СИГт┐ЃтцЇтѕХтц▒У┤Цт░▒С╝џт»╝УЄ┤Тћ»тЄ║у╝ЊтГўућ▒С║јС║ІС╗ХСИбтц▒ТѕќТ╗ътљјУђїтц▒ТЋѕсђѓжђџтИИ№╝їт╣┐тЉітЏъУ░Ѓу«АжЂЊС╝џтЄ║уј░у│╗у╗ЪжЌ«жбў№╝їСЙІтдѓтъЃтюЙТћХжЏєтЂюжА┐ТѕќТЋ░ТЇ«СИГт┐ЃуџёСИЇтЈ»жЮауйЉу╗юУ┐ъТјЦт»╝УЄ┤уџёС║ІС╗Хтцёуљєт╗ХУ┐Ъсђѓућ▒С║јУ┐ЎС║ЏжЌ«жбўтЈЉућЪтюеТЋ░ТЇ«СИГт┐ЃТюгтю░№╝їУ»ЦТЋ░ТЇ«СИГт┐ЃСИГуџё LSC ТјЦТћХтѕ░уџёС║ІС╗ХСИјт╗ХУ┐ЪТѕљТГБТ»ћ№╝їтЏаТГцТћ»тЄ║у╝ЊтГўуџёТЏ┤Тќ░С╣Ът░єт╗ХУ┐Ъ№╝їС╗јУђїт»╝УЄ┤УХЁТћ»сђѓ
тюеУ┐Єтј╗№╝їтдѓТъюСИђСИфТЋ░ТЇ«СИГт┐ЃтЈЉућЪУ┐ЎС║ЏТЋЁжџю№╝їТѕЉС╗гС╝џудЂућеУ┐ЎСИфТЋ░ТЇ«СИГт┐Ѓуџё LSC№╝їт╣ХУ«ЕтЁХС╗ќТЋ░ТЇ«СИГт┐Ѓуџё LSC тљїТЌХТЏ┤Тќ░Тюгтю░у╝ЊтГўтњїтЈЉућЪТЋЁжџюуџёТЋ░ТЇ«СИГт┐Ѓуџё LSC№╝їуЏ┤тѕ░тЄ║уј░Т╗ътљјуџёт╣┐тЉіУ░Ѓу«АжЂЊтњї LSC жЄЇТќ░У┐йСИіТЮЦсђѓ
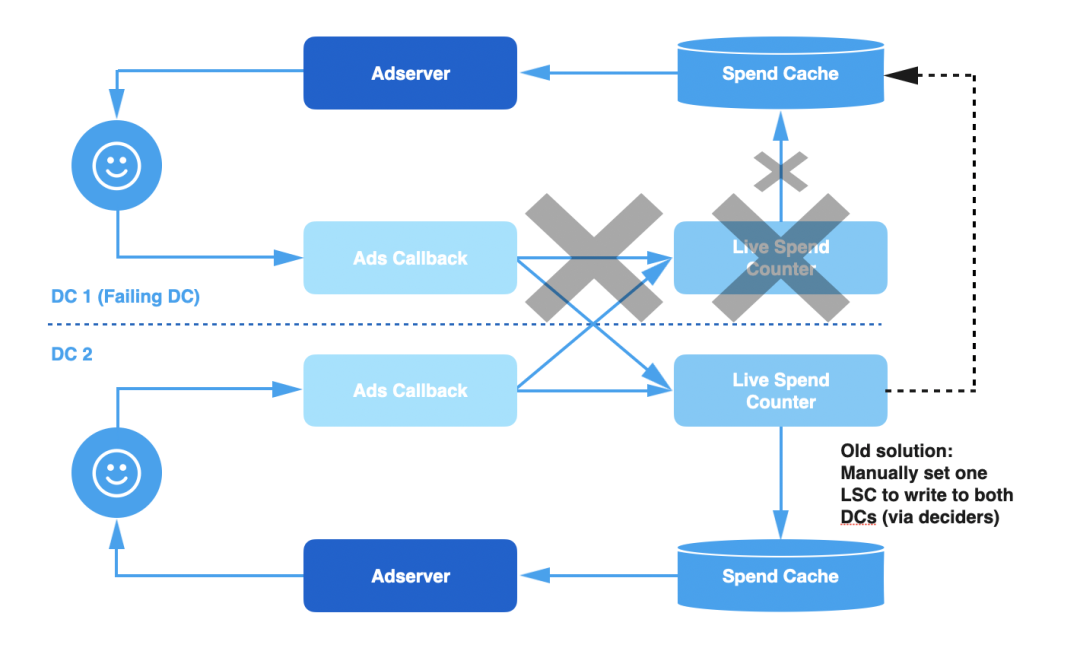
У┐ЎуДЇУДБтє│Тќ╣Т│ЋТюЅТЋѕтю░жЂ┐тЁЇС║єСИ┤ТЌХТђДуџёУХЁТћ»жЌ«жбў№╝їСйєС╗ЇуёХТюЅтЄаСИфСИЇУХ│уџётю░Тќ╣№╝џ
ТЅІтіетѕЄТЇб№╝џтљ»ућеУиеТЋ░ТЇ«СИГт┐ЃтєЎтЁЦТў»СИђСИфТЅІтіеТЅДУАїуџёУ┐ЄуеІ№╝їжюђУдЂТїЅСИђт«џуџёжА║т║ЈУ┐ЏУАїтцџСИфУ«Йуй«ТЏ┤Тћ╣сђѓТѕЉС╗гТюђу╗ѕСй┐ућеС║єУёџТюг№╝їСйєС╗ЇуёХжюђУдЂСИђСИфтЙЁтЉйтиЦуеІтИѕТЅІтіеТЅДУАїУёџТюгсђѓ
ТЅІтіежђЅТІЕТЋ░ТЇ«СИГт┐Ѓ№╝џжюђУдЂСИђСИфтїЁтљФтцџСИфТГЦжфцуџёТЅІтіеТЅДУАїУ┐ЄуеІТЮЦуА«т«џтЊфСИфТЋ░ТЇ«СИГт┐ЃТў»тЂЦт║иуџёС╗ЦтЈітљ»ућеУиеТЋ░ТЇ«СИГт┐ЃтєЎтЁЦТў»тљдт«ЅтЁесђѓтйЊТЋЁжџюТЂбтцЇжюђУдЂтЏътѕ░тѕЮтДІжЁЇуй«ТЌХ№╝їт┐ЁжА╗жЄЇтцЇу▒╗С╝╝уџёУ┐ЄуеІсђѓТюЅТЌХтђЎ№╝їУ┐ЎСИфУ┐ЄуеІжюђУдЂТЮЦУЄфСИЇтљїтЏбжўЪуџётцџСИфтЙЁтЉйтиЦуеІтИѕтЁ▒тљїтіфтіЏсђѓ
жФўУ┐љу╗┤ТѕљТюг№╝џућ▒С║ју«АуљєтиЦСйютї║ТХЅтЈіС║єтцџСИфТЅІтіеТГЦжфц№╝їтЏъУ░ЃтЪ║уАђУ«ЙТќйжЌ«жбўС╝џтИдТЮЦтЙѕжФўуџёУ┐љу╗┤ТѕљТюгсђѓ
- УиеТЋ░ТЇ«СИГт┐ЃтєЎтЁЦТќ╣ТАѕ -
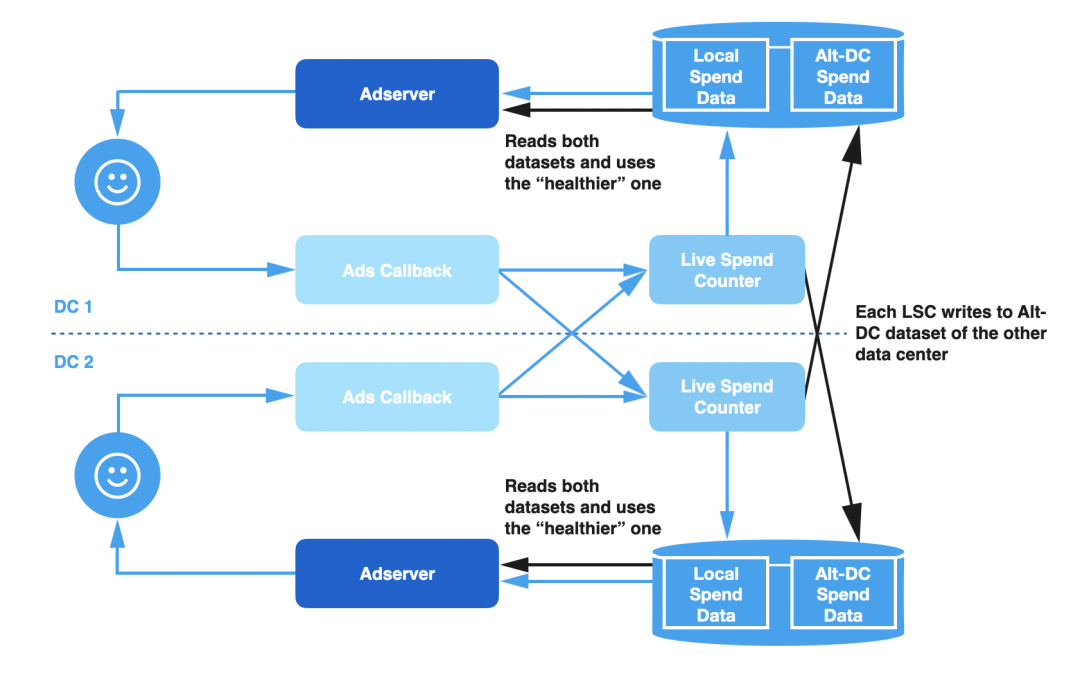
ућ▒С║јУ┐ЎуДЇТъХТъётГўтюетЙѕтцџжЌ«жбў№╝їТѕЉС╗гжЄЇТќ░У«ЙУ«АС║єу«АжЂЊ№╝їУ«Ет«ЃУЃйТЏ┤ТюЅт╝╣ТђДтю░т║ћт»╣ТЋЁжџю№╝їт╣ХтЄЈт░ЉУ┐љу╗┤С║║тЉўуџёт╣▓жбёсђѓУ┐ЎСИфУДБтє│Тќ╣ТАѕТюЅСИцСИфСИ╗УдЂу╗ёТѕљжЃетѕє№╝џ
УиеТЋ░ТЇ«СИГт┐ЃтєЎтЁЦ№╝џLSC Тђ╗Тў»тљїТЌХТЏ┤Тќ░РђютцЄућеРђЮТЋ░ТЇ«СИГт┐ЃуџёТћ»тЄ║у╝ЊтГўтњїТюгтю░у╝ЊтГўсђѓт«ЃУ┐ўС╝џтєЎтЁЦСИђС║ЏТюЅтЁ│ТЋ░ТЇ«У┐љУАїуіХтєхуџётЁЃТЋ░ТЇ«сђѓТ»ЈСИф LSC т«ъСЙІу╗┤ТіцСИцСИфтЇЋуІгуџёТЋ░ТЇ«жЏє№╝їСИђСИфтЈфУ«Ау«ЌТюгтю░уџёС┐АТЂ»№╝їтЈдСИђСИфтЈфУ«Ау«ЌТЮЦУЄфУ┐юуеІт«ъСЙІтєЎтЁЦуџёТЋ░ТЇ«сђѓ
ТЋ░ТЇ«жЏєтЂЦт║иТБђТЪЦ№╝џтюетцёуљєУ»иТ▒ѓТЌХ№╝їт╣┐тЉіТюЇтіАтЎеу«АжЂЊУ»╗тЈќСИцСИфуЅѕТюгуџёТЋ░ТЇ«№╝їт╣ХТа╣ТЇ«тЊфСИфТЋ░ТЇ«жЏєТЏ┤тЂЦт║иУЄфтіежђЅТІЕСй┐ућетЊфСИфуЅѕТюгсђѓ
тюеТГБтИИТЃЁтєхСИІ№╝їТќ░УДБтє│Тќ╣ТАѕуџётиЦСйютјЪуљєСИјС╣ІтЅЇуџёУ«ЙУ«Ат«їтЁеСИђУЄ┤сђѓСйєТў»№╝їтдѓТъюТюгтю░Тћ»тЄ║у╝ЊтГўУљйтљјС║є№╝їт╣┐тЉіТюЇтіАтЎеУЃйтцЪТБђТхІтѕ░№╝їт╣ХУЄфтіетѕЄТЇбтѕ░тїЁтљФТЮЦУЄфУ┐юуеІтєЎтЁЦТЋ░ТЇ«уџёТЋ░ТЇ«жЏєсђѓтйЊТюгтю░уџёжЌ«жбўУДБтє│С╣Ітљј№╝їт╣┐тЉіТюЇтіАтЎет░єУЄфтіетѕЄТЇбтЏъТюгтю░ТЋ░ТЇ«жЏєсђѓ
ТѕЉС╗гТђјС╣ѕуЪЦжЂЊтЊфСИфТЋ░ТЇ«жЏєТЏ┤тЂЦт║и№╝Ъ
ТѕЉС╗гжђџУ┐ЄтИИУДЂуџёТЋЁжџютю║ТЎ»ТЮЦтє│т«џТЋ░ТЇ«жЏєуџётЂЦт║иТЃЁтєх№╝џ
т╗ХУ┐Ъ№╝џтйЊт╣┐тЉітЏъУ░Ѓу«АжЂЊ/LSC ТЌаТ│ЋтЈіТЌХтцёуљєтцДжЄЈуџёС║ІС╗Х№╝їт░▒С╝џтЄ║уј░т╗ХУ┐ЪсђѓС║ІС╗ХТў»ТїЅуЁДт«ЃС╗гтѕ░УЙЙуџёжА║т║Јтцёуљєуџё№╝їТЅђС╗ЦТѕЉС╗гТЏ┤тђЙтљЉС║јжђЅТІЕтїЁтљФТюђТќ░С║ІС╗ХуџёТЋ░ТЇ«жЏєсђѓ
СИбтц▒С║ІС╗Х№╝џтюеТЪљС║ЏТЋЁжџютю║ТЎ»СИГ№╝їС║ІС╗ХтЈ»УЃйС╝џт«їтЁеСИбтц▒ТјЅсђѓСЙІтдѓ№╝їтдѓТъют╣┐тЉітЏъУ░Ѓу«АжЂЊуџёУиеТЋ░ТЇ«СИГт┐ЃтцЇтѕХтц▒У┤Ц№╝їтЁХСИГСИђСИфТЋ░ТЇ«СИГт┐Ѓт░єСИбтц▒СИђС║ЏУ┐юуеІС║ІС╗ХсђѓтЏаСИ║ТЅђТюЅуџёТЋ░ТЇ«СИГт┐ЃжЃйт║ћУ»ЦтцёуљєТЅђТюЅуџёС║ІС╗Х№╝їТЅђС╗ЦТѕЉС╗гт║ћУ»ЦжђЅТІЕтцёуљєС║єТюђтцџС║ІС╗ХуџёжѓБСИфТЋ░ТЇ«жЏєсђѓ
СИ║С║єТъёт╗║СИђСИфтїЁтљФУ┐ЎСИцСИфтЏау┤ауџётЂЦт║иТБђТЪЦТю║тѕХ№╝їТѕЉС╗гт╝ЋтЁЦС║єТћ»тЄ║уЏ┤Тќ╣тЏЙуџёТдѓт┐хсђѓ
- Тћ»тЄ║уЏ┤Тќ╣тЏЙ -
тЂЄУ«ЙТѕЉС╗гТюЅСИђСИфТ╗џтіеуфЌтЈБ№╝їТўЙуц║Т»ЈСИфТЋ░ТЇ«СИГт┐Ѓуџё LSC тюеС╗╗ТёЈу╗Ўт«џТЌХтѕ╗ТГБтюетцёуљєуџёС║ІС╗ХУ«АТЋ░сђѓТ╗џтіеуфЌтЈБтїЁтљФТюђУ┐Љ 60 уДњтєЁТ»ЈТ»ФуДњтцёуљєС║єтцџт░ЉС║ІС╗ХуџёУ«АТЋ░сђѓтйЊтѕ░УЙЙуфЌтЈБуџёТюФт░Й№╝їТѕЉС╗гтѕажЎцтц┤жЃеуџёУ«АТЋ░№╝їт╣ХУ«Ау«ЌтљјжЮб 1 Т»ФуДњуџёУ«АТЋ░сђѓТѕЉС╗гтЈ»С╗ЦуюІтѕ░ LSC тюе 60 уДњтєЁтцёуљєуџёРђюС║ІС╗ХУ«АТЋ░РђЮуџёуЏ┤Тќ╣тЏЙсђѓуЏ┤Тќ╣тЏЙтдѓСИІтЏЙТЅђуц║№╝џ
СИ║С║єУЃйтцЪжђЅТІЕТюђСй│уџёТЋ░ТЇ«жЏє(тюет╣┐тЉіТюЇтіАуФ»)№╝їТѕЉС╗гтѕЕућеС║єУ┐ЎСИфуЏ┤Тќ╣тЏЙтњїТюђУ┐ЉуџёС║ІС╗ХТЌХжЌ┤Тѕ│сђѓLSC т░єУ┐ЎС║ЏтЁЃТЋ░ТЇ«СИјТћ»тЄ║ТЋ░ТЇ«СИђУхитєЎтЁЦТћ»тЄ║у╝ЊтГўсђѓ
LSC тюетєЎтЁЦТЌХСИЇС╝џт║ЈтѕЌтїќ/тЈЇт║ЈтѕЌтїќТЋ┤СИфуЏ┤Тќ╣тЏЙсђѓтюетєЎтЁЦС╣ІтЅЇ№╝їт«ЃС╝џТ▒ЄТђ╗уфЌтЈБСИГТЅђТюЅУ«АТЋ░тЎеуџёУ«АТЋ░№╝їт╣ХтєЎтЁЦСИђСИфУЂџтљѕтђ╝сђѓУ┐ЎжЄїСй┐ућеС║ІС╗ХуџёУ┐ЉС╝╝тђ╝т░▒УХ│тцЪС║є№╝їУ┐ЉС╝╝тђ╝тЈ»С╗ЦСйюСИ║У┐ЎСИфТЋ░ТЇ«СИГт┐Ѓуџё LSC Тђ╗СйЊтЂЦт║иуіХтєхуџёС┐АтЈисђѓУ┐ЎТў»ућ▒ТЋЁжџюуџёТюгУ┤етє│т«џуџёРђћРђћтдѓТъюТЋЁжџюУХ│тцЪСИЦжЄЇ№╝їТѕЉС╗гт░єуФІтЇ│уюІтѕ░ТЋЁжџюуџётй▒тЊЇ№╝їУ«АТЋ░С╝џТўЙУЉЌСИІжЎЇсђѓтдѓТъюСИЇТў»тЙѕСИЦжЄЇуџёУ»Ю№╝їТЋ░жЄЈтЄаС╣јТў»СИђТаиуџёсђѓ
тїЁтљФтЁЃТЋ░ТЇ«уџёу╗ЊТъёСйЊТў»У┐ЎТаиуџё№╝џ
struct┬аSpendHistogram┬а{┬а┬а┬а┬аi64┬аapproximateCount;┬а┬а┬а┬аi64┬аtimestampMilliSecs;}
тцЇтѕХС╗БуаЂ
тюетцёуљєУ»иТ▒ѓТЌХ№╝їт╣┐тЉіТюЇтіАтЎетљїТЌХУ»╗тЈќТюгтю░тњїУ┐юуеІуџёТЋ░ТЇ«жЏєсђѓт«ЃСй┐уће SpendHistogram Та╣ТЇ«СИІжЮбТЈЈУ┐░уџёТЋ░ТЇ«СИГт┐ЃжђЅТІЕжђ╗УЙЉТЮЦтє│т«џСй┐ућетЊфСИфТЋ░ТЇ«жЏєСйюСИ║С║Іт«ъТЋ░ТЇ«ТЮЦТ║љсђѓ
- ТЋ░ТЇ«СИГт┐ЃуџёжђЅТІЕ -
жђЅТІЕТЋ░ТЇ«жЏєуџёжђ╗УЙЉтдѓСИІ№╝џ
┬и С╗јСИцСИфТЋ░ТЇ«СИГт┐ЃУјитЈќ SpendHistogramсђѓ
┬и ждќжђЅтЁиТюЅТюђТќ░ТЌХжЌ┤Тѕ│тњїТюђжФўС║ІС╗ХУ«АТЋ░уџёТЋ░ТЇ«жЏєсђѓ
┬и тдѓТъют«ЃС╗гжЮътИИуЏИУ┐ЉСИћжЃйтцёС║јТГБтИИуіХТђЂ№╝їт░▒ждќжђЅТюгтю░ТЋ░ТЇ«жЏє№╝їУ┐ЎТаитЈ»С╗ЦжЂ┐тЁЇућ▒С║јт░Јуџёт╗ХУ┐ЪУђїтюеСИцСИфТЋ░ТЇ«СИГт┐ЃС╣ІжЌ┤ТЮЦтЏътѕЄТЇбсђѓ
У┐ЎтЈ»С╗ЦТђ╗у╗ЊТѕљС╗ЦСИІуџёуюЪтђ╝УАе№╝џ
x = LocalTimeStamp - RemoteTimeStamp
y = LocalApproxCount - RemoteApproxCount
ts = ThresholdTimeStamp
tc = ThresholdApproxCountPercent
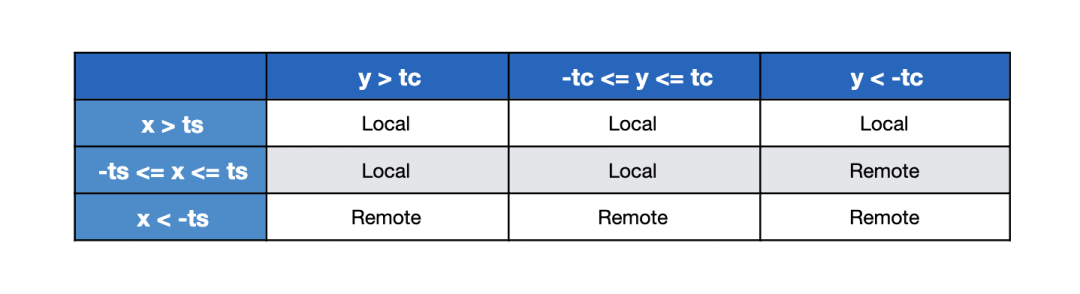
тюетѕЄТЇбтѕ░Сй┐ућеТЮЦУЄфУ┐юуеІТЋ░ТЇ«СИГт┐ЃуџёТЋ░ТЇ«жЏєС╣ІтЅЇ№╝їТѕЉС╗гСй┐уће ts тњї tc ТЮЦуА«т«џт«╣т┐Їт║джўѕтђ╝сђѓтдѓТъюти«тђ╝тюежўѕтђ╝тєЁ№╝їТѕЉС╗гС╝џТЏ┤тђЙтљЉС║јСй┐ућеТюгтю░ТЋ░ТЇ«жЏєсђѓТѕЉС╗гт░ЮУ»ЋТЅЙтѕ░жўѕтђ╝№╝їС╗ЦСЙ┐тюеСИЇжюђУдЂУ┐ЏУАїТЋ░ТЇ«СИГт┐ЃтѕЄТЇбуџёТЃЁтєхСИІт░йТЌЕТБђТхІТЋЁжџюсђѓт╣┐тЉіТюЇтіАтЎетюетцёуљєТ»ЈСИфУ»иТ▒ѓТЌХжЃйС╝џтЈЉућЪУ┐ЎСИфжђЅТІЕУ┐ЄуеІ№╝їтЏаТГцТѕЉС╗гС╝џтюеТюгтю░У┐ЏУАїу╝ЊтГў№╝їТ»ЈжџћтЄауДњтѕиТќ░СИђТгА№╝їС╗Цжў▓ТГбжбЉу╣ЂуџёуйЉу╗юУ«┐жЌ«тй▒тЊЇТЋ┤СйЊТђДУЃйсђѓ
СИІжЮбТў»тѕЄТЇбСй┐ућеТЋ░ТЇ«СИГт┐ЃТЋ░ТЇ«уџётЈ»УДєтїќУАеуц║сђѓтйЊ DC1 уџё LSC тЈЉућЪТЋЁжџюТЌХ№╝їС╝џт»╝УЄ┤ DC1 уџёт╣┐тЉіТюЇтіАтЎеУЄфтіежђЅТІЕСй┐уће DC2 уџёТЋ░ТЇ«сђѓ
- ТЅЕт▒Ћтѕ░тцџСИфТЋ░ТЇ«СИГт┐Ѓ -
тѕ░уЏ«тЅЇСИ║ТГб№╝їТѕЉС╗гУ«еУ«║уџёТќ╣Т│ЋтЈфТХЅтЈіСИцСИфТЋ░ТЇ«СИГт┐ЃсђѓжђџУ┐Єт╝ЋтЁЦУиеТЋ░ТЇ«СИГт┐ЃтцЇтѕХтЏатГљуџёТдѓт┐х№╝їТѕЉС╗гтЈ»С╗Цт░єУ«ЙУ«АТЅЕт▒Ћтѕ░РђюNРђЮСИфТЋ░ТЇ«СИГт┐ЃсђѓтцЇтѕХтЏатГљТјДтѕХТ»ЈСИф LSC ТюЇтіАтєЎтЁЦуџёУ┐юуеІТЋ░ТЇ«СИГт┐ЃуџёТЋ░жЄЈсђѓтюеУ»╗тЈќТЋ░ТЇ«ТЌХ№╝їТѕЉС╗гСй┐ућеС║єуЏИтљїуџёжђ╗УЙЉ№╝їт╣ХтЂџС║єСИђС║ЏС╝ўтїќ№╝їТ»ћтдѓСИђТгАУ»╗тЈќ(ТЅ╣У»╗тЈќ)ТЅђТюЅт┐ЁУдЂТЋ░ТЇ«№╝їУђїСИЇТў»тѕєтцџТгАУ»╗тЈќсђѓ
СЙІтдѓ№╝їтЂЄУ«Й ReplicationFactor У«Йуй«СИ║ 2№╝їDC1 СИГуџё LSC т░єтєЎтЁЦтѕ░ DC1сђЂDC2 тњї DC3 уџёТћ»тЄ║у╝ЊтГў№╝їDC2 СИГуџё LSC т░єтєЎтЁЦтѕ░ DC2сђЂDC3 тњї DC4 уџёТћ»тЄ║у╝ЊтГў№╝їDC3 СИГуџё LSC т░єтєЎтЁЦтѕ░ DC3сђЂDC4 тњї DC1 уџёТћ»тЄ║у╝ЊтГўсђѓСИІтЏЙТўЙуц║С║єСИЅСИфТЋ░ТЇ«СИГт┐ЃуџётцЇтѕХтјЪуљєтЏЙсђѓтюеТ»ЈСИфТЋ░ТЇ«СИГт┐ЃСИГ№╝їт╣┐тЉіТюЇтіАтЎет░єУ»╗тЈќСИЅСИфТћ»тЄ║уЏ┤Тќ╣тЏЙ№╝їт╣ХС╗јТЅђТюЅУ┐ЎС║ЏТЋ░ТЇ«СИГт┐ЃжђЅТІЕждќжђЅуџёТЋ░ТЇ«жЏєсђѓТа╣ТЇ«ТѕЉС╗гуџёуйЉу╗ютњїтГўтѓеу║дТЮЪ№╝їТѕЉС╗гжђЅТІЕ 2 СйюСИ║тцЇтѕХтЏатГљсђѓ
- у╗ЊУ«║ -
тюеТјетЄ║У┐ЎС║ЏтЈўТЏ┤С╣Ітљј№╝їТѕЉС╗гТ│еТёЈтѕ░тЏбжўЪуџёУ┐љу╗┤ТѕљТюгтЈЉућЪС║єжЄЇтцДтЈўтїќсђѓС╣ІтЅЇТ»ЈСИфтГБт║дућ▒С║ју│╗у╗ЪжЌ«жбўС╝џт»╝УЄ┤тцџТгАУХЁТћ»С║ІС╗Х№╝їУђїтюеУ┐Єтј╗уџёСИђт╣┤№╝їжЃйТ▓АТюЅтЈЉућЪТГцу▒╗С║ІС╗ХсђѓУ┐ЎУіѓуюЂС║єтцДжЄЈуџётиЦуеІТЌХжЌ┤№╝їт╣ХжЂ┐тЁЇС║єућ▒С║јтЪ║уАђУ«ЙТќйжЌ«жбўУђїтљЉт╣┐тЉітЋєтЈЉТћЙУАЦтЂ┐сђѓ
жђџУ┐ЄУ»єтѕФу│╗у╗ЪтЂЦт║итЁ│жћ«ТїЄТаЄ№╝їУ«ЙУ«АтЄ║Тюђу«ђтЇЋуџётиЦуеІУДБтє│Тќ╣ТАѕ№╝їт╣ХТа╣ТЇ«У┐ЎС║ЏТїЄТаЄУЄфтіежЄЄтЈќУАїтіе№╝їТѕЉС╗гУДБтє│С║єСИђСИфтй▒тЊЇТюЇтіАу«АжЂЊТГБуА«ТђДуџётЁ│жћ«ТђДжЌ«жбўсђѓТѕЉС╗гСИЇС╗ЁТъёт╗║С║єСИђСИфтЁиТюЅт«╣жћЎУЃйтіЏтњїт╝╣ТђДуџёу│╗у╗Ъ№╝їУђїСИћжЄіТћЙС║єтиЦуеІУхёТ║љ№╝їТііт«ЃС╗гућетюеТЏ┤ТюЅС╗итђ╝уџётю░Тќ╣сђѓ
- тдѓСйЋтюеiPhoneСИіт┐ФжђЪТЅЙтѕ░TikTokтЦйтЈІ№╝ЪУ┐ЎСИцСИфу«ђтЇЋТќ╣Т│ЋУй╗ТЮЙТљът«џ№╝Ђ
- тЏйтєЁућеТѕитдѓСйЋСИІУййтњїСй┐ућеTikTok№╝ЪУІ╣Тъютњїт«ЅтЇЊУ«ЙтцЄТюЅСИЇтљїУдЂТ▒ѓтљЌ№╝Ъ
- СИ╗У┤дтЈиСИјтЅ»У┤дтЈитдѓСйЋжЁЇтљѕуЏ┤ТњГ№╝ЪТЈГуДўтцДтЈиу▓ЅСИЮтбъжЋ┐уџёуДўУ»ђ№╝Ђ
- TikTokУй»Уи»ућ▒уюЪуџёТюЅт┐ЁУдЂтљЌ№╝ЪтдѓСйЋУ«ЕСйауџёуйЉжђЪТ»ћтѕФС║║т┐Ф№╝Ъ
- тЏйтєЁТЌаТ│ЋТГБтИИСй┐ућеTikTok№╝ЪУ┐ЎС║ЏУ«Йуй«СйауЪЦжЂЊС║єтљЌ№╝Ъ
- TikTokтИдУ┤ДТЮЃжЎљтдѓСйЋућ│У»и№╝ЪтЋєтЊЂТЕ▒уфЌУй╗ТЮЙтЈўуј░№╝їСйатГдС╝џС║єтљЌ№╝Ъ
- СИ║С╗ђС╣ѕтЏйтєЁтй▒УДєтЅфУЙЉСИЇУхџжњ▒С║є№╝ЪTikTokУЃйтљдТѕљСИ║СйауџёСИІСИђСИфУхџжњ▒тѕЕтЎе№╝Ъ
- TikTokуЪГУДєжбЉтИдУ┤ДТђјТаиТЅЇУЃйТюѕУхџ20СИЄ№╝Ът░ЈтЏбжўЪтдѓСйЋт┐ФжђЪт«ъуј░жФўТћХуЏі№╝Ъ








